A few years ago in a conference, I have heard about a method that is used to find solutions to combinatorial problems which are usually very hard to solve. The method is called
Difference Map. Given two sets, Difference Map (DM) finds a point that belongs to both sets. In other words it finds a point in the intersection of two sets. The method utilizes projections onto the given sets.
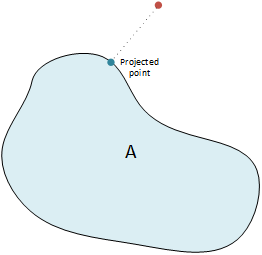 |
| Projection onto a set means finding a point in the set that minimizes the distance to a given point. |
Typically each constraint of your problem defines a set. If you have more than two constraints, there is a trick, called
Divide and Concur, to combine them into two sets and perform regular DM.
I have implemented a Sudoku solver using this approach. Sudoku is a constraint satisfaction problem and fits to this approach with proper definition of constraints. Make sure to check it out
here.
Let's define these approaches formally and build the basis for the Sudoku solver. I will skim over some of the details to keep things compact and casual.
Difference Map
Say you have two sets $A$ and $B$ and you can project a given point to these sets via functions $P_A(\cdot)$ and $P_B(\cdot)$.
A naive approach would be to select an initial point and project it onto $A$ and then $B$ and repeat the process until convergence. This procedure of applying a function repeatedly is often called
fixed point iteration.
$$
x_{k+1} \leftarrow P_B(P_A(x_k))
$$This works if the sets are convex. If the sets are not convex, this fixed point iteration has no guarantees and fails to provide a solution most of the time. We can do better than that, consider:
$$
x_{k+1} \leftarrow x_k + P_A(2P_B(x_k)-x_k)-P_B(x_k)
$$ If this scheme ever converges (i.e. $x_{k+1} = x_k$), it means that $P_A(2P_B(x_k)-x_k)-P_B(x_k) = 0$. Following this $P_A(x_k) = P_B(x_k)$. This means that we have found point contained in both sets!
This is all very good, now let's introduce a hyperparameter to allow us to fine tune the algorithm for different problems.
$$
x_{k+1} \leftarrow x_k + \beta \left( P_A(f_B(x_k)) - P_B(f_A(x_k)) \right)
$$ where
$$
f_A(x) = P_A(x) - \frac1{\beta}(P_A(x) - x) \\
f_B(x) = P_B(x) + \frac1{\beta}(P_B(x) - x)
$$
We have just defined Difference Map algorithm. Note that the expressions above are equal to the previous expression for $\beta=1$.
Divide and Concur
To use DM you need to define your constraints as two different sets and you need to define projection operations onto those sets. Expressing your problem exactly as two sets might not be easy for every task. We need a way of using the same framework with many constraints.
Say, you have $N$ constraints and associated projection operations defined by these constraints $P_1(\cdot), P_2(\cdot), \dots, P_N(\cdot)$. Roughly, DC works in an $N$ times larger space. Say a point in this space is $x=(x_1 x_2 \dots x_N)$. $P_A(x)$ projects a given point onto $N$ different sets ($x_i$ to set $i$) and concatenates the results. $P_B(\cdot)$ averages them out at each step. More formally, we put together these different constraints together in a Difference Map framework by defining:
$$
\begin{align*}
P_A(x) &= \text{concat}(P_1(x_1), P_2(x_2), \dots, P_N(x_N)) \\
P_B(x) &= \text{concat}(\bar{x}, \bar{x}, \dots, \bar{x})
\end{align*}
$$ where $\bar{x}$ is the mean of $\{x_1, \dots, x_N\}$.
Solving Sudoku with Divide and Concur
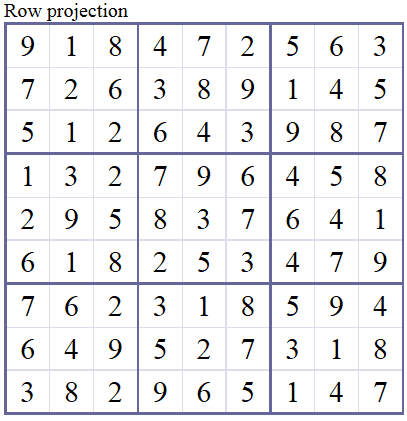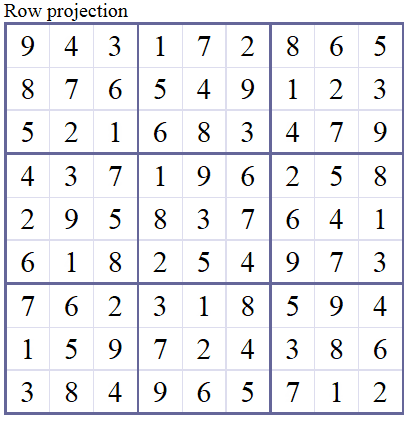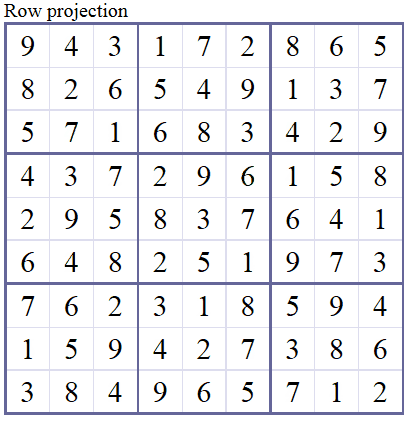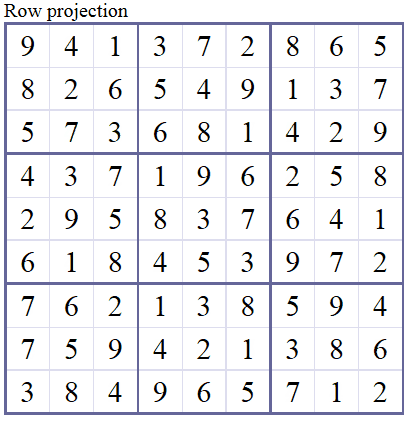
We will represent Sudoku grid with a $9\times9\times9$ array, if the element at $(i,j,k)$ is $1$ that means there is a symbol $k$ in cell $(i,j)$. The rest is filled with zeroes.
Using this representation we have 4 constraints. We are familiar with three of the constraints, they are the very foundations of Sudoku: Each row, column and $3\times3$ block contains only one of each symbol. The fourth one is a little bit different, it is the direct result of the $9\times9\times9$ representation we use: there should be only single symbol at each cell. If we don't put this constraint we may have fractional symbols at each cell. For example we may have a solution where at a cell there is 0.7 "4", 0.1 "6" and 0.2 "9" (note that they sum up to 1).
Given a possibly fractional state $x$ the projection onto a $i^\text{th}$ row constraint is finding the configuration $p(j)$ that minimizes $-\sum_{j=1}^9 x_{ijp(j)}$. I won't give details to keep things simple, you can check out the original paper. This assignment problem can be solved quickly using the famous Munkres (a.k.a. Hungarian) algorithm.
Column and block constraints are very similar in their nature, the same approach can be used for them. For a cell, projection onto the set defined by symbol constraint is finding the symbol with minimum value in $-x$, in other words $\arg \min_k -x_{ijk}$ for cell $(i,j)$.
Solver in Action
Check out my DC implementation of Sudoku
here. Source code is also available on
github.
A MATLAB implementation is also available in the repository. I didn't realize how MATLAB makes life easier when you work with matrices until I started to port it into Javascript. I used math.js library but all the indexing and range operators didn't make life easier.
References
Elser, Veit, I. Rankenburg, and P. Thibault. "Searching with iterated maps." Proceedings of the National Academy of Sciences 104, no. 2 (2007): 418-423.
Gravel, Simon, and Veit Elser. "Divide and concur: A general approach to constraint satisfaction." Physical Review E 78, no. 3 (2008): 036706.



.jpg)